
מודל ההסקה של Alibaba

המודל החדש QwQ-32B-Preview של Alibaba, שפותח על ידי צוות Qwen, נועד לשפר יכולות חשיבה לוגית ופתרון בעיות, ומעמיד את עצמו כמתחרה משמעותי למודלים של OpenAI מסדרת o1. עם 32.5 מיליארד פרמטרים ויכולת לעבד הקשר של עד 32,000 מילים, QwQ-32B-Preview הפגין ביצועים תחרותיים במבחני מדדים כגון AIME ו-MATH.
המודל זמין לשימוש מסחרי תחת רישיון קוד פתוח Apache 2.0.
מערכת האימות העצמי של QwQ

אחת התועלות המרכזיות של מערכת האימות העצמי היא שיפור יכולות הלמידה ממספר מצומצם של דוגמאות (few-shot learning) במשימות כגון חילוץ מידע רפואי.
באמצעות אימות תוצריו, QwQ עשוי לשפר את ביצועיו במצבים בהם זמינים נתוני אימון מוגבלים, מה שמקנה לו ערך רב במיוחד בתחומים מתמחים כמו רפואה. יישום האימות העצמי ב-QwQ תורם גם לביצועיו התחרותיים מול מודלים מתקדמים אחרים.
בבדיקות מקיפות בתחומים כמו תכנות, חשיבה לוגית ומדדי בטיחות, QwQ הפגין יכולות מרשימות שעמדו ברמה שווה למודלים מתקדמים כמו GPT-4, Claude 3.5 Sonnet, ומודלי o1 Mini של OpenAI.
עם זאת, חשוב לציין כי למרות שמערכות אימות עצמי משפרות את איכות התוצרים, הן אינן חפות מטעויות. יעילותן עשויה להשתנות בהתאם למורכבות המשימה וליישום הספציפי של המערכת. כמו בכל מודל בינה מלאכותית, מומלץ להתייחס לתוצרים של QwQ בעין ביקורתית, במיוחד במצבים קריטיים.
אופי הקוד הפתוח של QwQ-32B-Preview מאפשר לקהילה הרחבה לחקור ולשפר את יכולות האימות העצמי שלו. שקיפות זו עשויה להוביל לשיפורים במנגנוני הבדיקה העצמית של המודל, ולהרחיב את גבולות ההיגיון והאמינות בבינה מלאכותית.
QwQ מול OpenAI o1 – מדדי ביצועים

המודל QwQ-32B-Preview הציג ביצועים מרשימים במיוחד במדדי ביצועים, במיוחד בהשוואה למודלים של OpenAI מסדרת o1. בניסויים שנערכו על ידי Alibaba, המודל QwQ-32B-Preview עלה על הביצועים של o1-preview ו-o1-mini במדדים AIME (American Invitational Mathematics Examination) ו-MATH. מדדים אלו חשובים במיוחד מאחר שהם מעריכים את יכולתו של המודל לפתור בעיות מתמטיות מורכבות ולבצע חשיבה ברמה גבוהה.
מבחן ה-AIME ייחודי בכך שהוא משתמש במודלים אחרים להערכת ביצועים, ובכך מספק הערכה מקיפה של יכולות QwQ. המדד MATH, הכולל בעיות מילוליות מאתגרות, מדגיש עוד יותר את המומחיות של QwQ בהבנה ופתרון של בעיות מתמטיות מורכבות.
מעבר לתחום המתמטיקה, QwQ-32B-Preview הפגין ביצועים תחרותיים במגוון משימות. במבחנים לתכנות, המודל הצליח להתמודד עם אתגרים ברמת קושי קלה ובינונית, אך הציג תוצאות מעורבות באתגרים ברמת מומחה. הדבר מצביע על כך ש-QwQ אמנם מסוגל מאוד במשימות תכנות כלליות, אך נותר מקום לשיפור בטיפול בתרחישים הקשים ביותר בתחום הקוד.
מעניין לציין כי הביצועים של QwQ-32B-Preview חורגים מעבר להשוואה למודלים של OpenAI. לפי דיווחים מסוימים, המודל עלה בביצועיו על GPT-4o ו-Claude 3.5 Sonnet במדדים שונים. עובדה זו מעידה על כך ש-QwQ לא רק מתחרה במודלים של OpenAI, אלא גם מציב רף גבוה לעומת מודלים מובילים אחרים בתעשייה.
עם זאת, יש לזכור כי ביצועים במדדים אינם תמיד משקפים ישירות את היישום בעולם האמיתי. QwQ-32B-Preview הציג מגבלות מסוימות, כגון תאימות לגרסאות Python, מה שמצביע על כך שיישום מעשי עשוי לדרוש התאמות עדינות לצרכים ספציפיים.
האופי הקוד הפתוח של QwQ-32B-Preview, הזמין בפלטפורמות כמו Hugging Face Spaces ותואם להתקנות מקומיות עם Ollama, מאפשר בדיקות ואימות רחבים יותר של תוצאות המדדים על ידי קהילת הבינה המלאכותית. שקיפות זו עשויה להוביל להשוואות מקיפות יותר ולשיפורים פוטנציאליים בעתיד.
היכולות הרב-לשוניות של QwQ

המודל QwQ-32B-Preview מציג יכולות רב-לשוניות מרשימות, המאפשרות לו לתקשר במגוון שפות וניבים. תכונה זו מועילה במיוחד ביישומים גלובליים שבהם גיוון לשוני הוא גורם קריטי. היכולת של המודל לערבב בין שפות או לעבור ביניהן, תהליך המכונה "code-switching", משפרת את התאמתו לסביבות רב-לשוניות. עם זאת, תכונה זו מציבה גם אתגרים: מעבר בלתי צפוי בין שפות עלול לפגוע בבהירות התשובות ולבלבל משתמשים המצפים לתשובה בשפה אחידה.
הכוח הרב-לשוני של QwQ-32B-Preview נתמך על ידי האופי הקוד הפתוח של המודל, שמאפשר למפתחים ברחבי העולם לכוון אותו מחדש לצרכים לשוניים והקשרים ספציפיים. גישה זו מעניקה לקהילת הבינה המלאכותית הזדמנות להתנסות ולשפר את יכולות הטיפול בשפה של המודל, מה שעשוי להוביל לאינטראקציות רב-לשוניות מדויקות וידידותיות יותר למשתמש.
למרות החוזקות הללו, עיבוד השפות של המודל אינו חף מבעיות. ערבוב בלתי צפוי של שפות עלול לפגוע בביצועיו במשימות הדורשות דבקות קפדנית בשפה אחת. עם זאת, היכולת של QwQ להתמודד עם מספר שפות נשארת נכס משמעותי, במיוחד במצבים שבהם תקשורת דו-לשונית או רב-לשונית היא הכרחית.
דרישות חומרה למודל QwQ

הרצת המודל QwQ-32B-Preview דורשת משאבים חישוביים משמעותיים, בעיקר בשל גודלו המכיל 32.5 מיליארד פרמטרים. כדי לנצל באופן מיטבי את יכולות המודל המתקדם, יש לקחת בחשבון את דרישות החומרה הבאות:
- זיכרון GPU: כרטיס גרפי עם לפחות 20GB של VRAM הוא הכרחי לביצועים אופטימליים. מקורות מסוימים מציינים כי כרטיס עם 24GB מתאים לרוב השימושים.
- זיכרון RAM: למרות שאין דרישות מוגדרות, מערכת עם 32GB או יותר של RAM תספק חוויית עבודה חלקה יותר.
- אחסון: מומלץ להשתמש בכונן SSD מהיר כדי להתמודד עם קבצי המודל הגדולים ולאפשר גישה מהירה לנתונים בזמן העבודה.
עבור משתמשים עם מחשבי Apple Silicon, מכשיר עם 48GB של זיכרון מאוחד יכול להריץ את המודל, מה שמדגיש את יעילות הארכיטקטורה של Apple בטיפול במודלי שפה גדולים.
התאמות בהתאם לשימוש:
- אורך הקשר: הצורך בזיכרון VRAM עשוי לגדול אם רוצים לעבד חלונות הקשר ארוכים יותר. QwQ-32B-Preview יכול להתמודד עם עד 32,000 מילים של הקשר, מה שעשוי לדרוש זיכרון נוסף לניצול מלא של היכולת הזו.
- כימות (Quantization): טכניקות כמו AWQ (Activation-aware Weight Quantization) יכולות להפחית את דרישות הזיכרון. גרסת AWQ של המודל דורשת כ-20GB של VRAM בלבד.
- פורמט GGUF: למשתמשים המעוניינים להריץ את המודל על חומרה ביתית, קיימות גרסאות בפורמט GGUF, שיכולות להפחית את דרישות החומרה.
התקנה מקומית:
הממשק תואם לפלטפורמות כמו Ollama, שיכולות לפשט את תהליך ההתקנה עבור משתמשים מסוימים.
חשוב להבין כי בעוד אלו הדרישות הכלליות, ביצועי המודל ויכולתו להתמודד עם משימות מורכבות, כגון הסקת מסקנות מתקדמת ופתרון בעיות מתמטיות, תלויים בכוח החישובי הזמין. מומלץ למשתמשים להתנסות בתצורות שונות כדי למצוא את ההגדרה האופטימלית לצרכים ולמגבלות החומרה שלהם.
התקנתי את המודל דרך Hugging Face אצלי על המחשב הנייד. הרצתי את המודל בעזרת LMStudio, המודל אומנם עובד ונותן תוצאות טובות אבל הוא איטי מאוד.
המודל שהתקנתי הוא QwQ-32B-Preview-i1-GGUF וגןדלו 9.03GB.
הרצת QwQ מקומית

כדי להריץ את המודל QwQ-32B-Preview על המחשב האישי שלך, יש לעקוב אחר השלבים הבאים, תוך התחשבות בדרישות החומרה שצוינו קודם:
1. בחירת גרסה מקווצת: כדי להתאים לחומרה ביתית, מומלץ להשתמש בגרסה מקווצת של המודל. פורמט GGUF (GPT-Generated Unified Format) מתאים במיוחד להרצה מקומית, שכן הוא מפחית את צריכת הזיכרון תוך שמירה על ביצועים.
2. הורדת המודל: ניתן למצוא גרסאות מקווצות של QwQ-32B-Preview בפלטפורמת Hugging Face. לדוגמה, הריפוזיטורי bartowski/QwQ-32B-Preview-GGUF מציע מספר גרסאות GGUF.
3. הקמת סביבת עבודה: יש להתקין מסגרת (framework) תואמת להרצת מודלים גדולים באופן מקומי. מומלץ להשתמש ב-LM Studio להרצת גרסאות GGUF. לחלופין, ניתן להשתמש ב-Ollama, שנמצא כמתאים היטב למודל QwQ-32B-Preview.
4. טעינת המודל: לאחר הקמת הסביבה, יש לטעון את קובץ המודל שהורד לתוך המסגרת שנבחרה.
5. הגדרת פורמט הפקודה (Prompt): המודל QwQ-32B-Preview משתמש בפורמט פקודה ייחודי. ודא שהממשק שלך מוגדר בהתאם למבנה הבא:
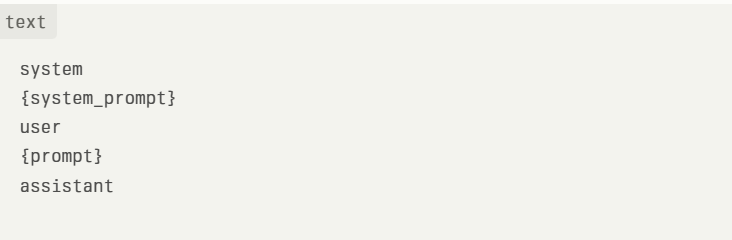
6. הרצה ואינטראקציה: לאחר טעינת המודל והגדרת הפורמט, ניתן להתחיל לתקשר עם QwQ-32B-Preview דרך הממשק שנבחר.
הערות ותובנות:
משאבים חישוביים: הרצת מודל בגודל זה מקומית יכולה להיות אינטנסיבית מבחינת משאבים. ייתכנו זמני תגובה איטיים בהשוואה לפתרונות מבוססי ענן, במיוחד אם החומרה קרובה לדרישות המינימום.
אתגרים אפשריים: יש להתכונן לאתגרים אפשריים כמו ערבוב שפות בלתי צפוי או לולאות חשיבה חוזרות.
גרסת AWQ: למשתמשים בעלי חומרה חזקה, מומלץ לשקול את גרסת AWQ (Activation-aware Weight Quantization), שמציעה איזון טוב בין ביצועים לבין צריכת משאבים. גרסה זו דורשת כ-20GB של VRAM ומתאימה לכרטיסי מסך מתקדמים כגון NVIDIA GeForce RTX 4090.
הרצה מקומית ואחריות:
הרצת מודלים בינה מלאכותית מקומית מחייבת אחריות. ודא שקיימות מערכות אבטחה מתאימות, במיוחד כשמדובר במודל המצריך שיקולים מוגברים של בטיחות. השתמש במודל באחריות ותמיד היה מודע למגבלותיו, כמו הבנת שפה מורכבת או היגיון כללי.
תובנות עיקריות על QwQ-32B-Preview

המודל QwQ-32B-Preview, שפותח על ידי צוות Qwen של Alibaba, מייצג התקדמות משמעותית ביכולות ההיגיון של בינה מלאכותית. זהו מודל מחקר ניסיוני הכולל 32.5 מיליארד פרמטרים, המסוגל לעבד פקודות באורך של עד 32,000 מילים. כמודל קוד פתוח שמתחרה במודל ההיגיון של OpenAI מסדרת o1, QwQ-32B-Preview מציג יכולות אנליטיות מבטיחות לצד מגבלות ניכרות.
יתרונות מרכזיים:
- תחומי מומחיות:
- מצטיין בתחומים כמו מתמטיקה ותכנות, עם ביצועים עדיפים על מתחרים כמו o1-preview ו-o1-mini במדדים כמו AIME ו-MATH.
- מפגין ביצועים חזקים במשימות תכנות, במיוחד באתגרים ברמת קושי קלה ובינונית.
- מערכת אימות עצמי:
- תכונה ייחודית המאפשרת למודל לתכנן מראש את תשובותיו ולבדוק אותן לפני הצגתן למשתמשים.
- משפרת את הדיוק והאמינות, במיוחד בתרחישים של למידה ממספר מצומצם של דוגמאות, כמו חילוץ מידע רפואי.
- נגישות בקוד פתוח:
- זמין תחת רישיון Apache 2.0, המאפשר שימוש מסחרי ופיתוח נוסף על ידי קהילת הבינה המלאכותית.
- גרסאות מקווצות, כגון GGUF ו-AWQ, זמינות בפלטפורמות כמו Hugging Face, ומאפשרות התקנה מקומית על חומרה ביתית.
מגבלות עיקריות:
- שפה והיגיון:
- המודל עלול לערבב שפות באופן בלתי צפוי או לעבור ביניהן, מה שפוגע בבהירות התשובות.
- קיימת נטייה ללולאות חשיבה מעגליות, היוצרות תגובות ארוכות ללא מסקנה ברורה.
- אמצעי אבטחה:
- נדרשות מערכות אבטחה משופרות כדי להבטיח ביצועים אמינים ובטוחים.
- מגבלות בהבנה:
- דרוש שיפור בהיגיון כללי ובהבנה מעמיקה של שפה.
פוטנציאל לעתיד:
כמודל ניסיוני, QwQ-32B-Preview מדגים את הפוטנציאל לקידום יכולות ההיגיון של בינה מלאכותית, תוך הצגת אתגרים מתמשכים בפיתוח מערכות AI רב-תפקודיות ואמינות. אופיו כמודל קוד פתוח מזמין את הקהילה להמשיך לחקור, לשפר ולפתח אותו, מה שעשוי להניע חדשנות נוספת בתחומי ההיגיון ופתרון הבעיות בבינה מלאכותית.
